| Topical Authority | 16 min read
Entity Schema for Topical Authority Guide
Learn how to map entities, build JSON-LD, validate schema, use sameAs links, and measure topical authority gains for AI search.
Entity schema for topical authority is a practical guide to modeling entities, relationships, and JSON-LD for stronger search visibility. SEO teams often need to prove subject matter depth without turning a site into a cluttered mix of tags, duplicate identities, and scattered page signals. It is the structured way search systems read people, brands, products, and concepts as connected signals. By the end, readers have a practical model for turning topical research into schema that supports a clear authority structure.
It covers how to map core entities, choose stable @id URIs, build a production JSON-LD graph, and validate sameAs links before launch. Aligned internal links and page architecture keep the entity layer from drifting as the site grows, while GEO signals and LLM citation behavior stay easier to interpret. Expect a reusable template for entity mapping, a production markup pattern, and a validation checklist.
For SEO agencies, content strategists, and technical SEO leads, the value is faster implementation with fewer review cycles and cleaner handoffs to engineering. One example shows a hub page keeping about on the primary entity while a support page carries adjacent concepts and verified sameAs targets. The result is a schema system that reads cleanly for search, AI, and internal teams.
Entity Schema Topical Authority Key Takeaways
- Entity schema links people, brands, products, and concepts into one machine-readable topical model.
- Stable
@idURIs keep identity consistent across pages, updates, and CMS changes. - The
aboutproperty should stay focused on the main entity, not every related concept. - Use
sameAsonly for authoritative profiles that match the exact real-world entity. - A production
@graphshould connect Article, Person, Organization, and topic nodes cleanly. - Validate syntax, entity links, and live-page parity before requesting reindexing.
- Measure authority with baseline scores, entity visibility, query coverage, and traffic distribution.
What Is Entity Schema For Topical Authority?
Entity schema for topical authority is the structured way you describe real-world entities and the relationships between them. Those entities can be people, organizations, products, places, events, and concepts. For Search Engine Optimization (SEO) systems, that structure turns expertise into a connected Knowledge Graph instead of a pile of isolated keywords.
That matters because topical authority grows when search systems can see the primary brand entity, the supporting concepts around it, and the way hub-and-spoke pages connect. The site becomes easier to read for crawlers and for humans. It also gives artificial intelligence (AI) systems clearer signals, which is why entity-based SEO keeps showing up in stronger search programs.
The scope here is practical, not theoretical. You are not tagging every sentence with schema or trying to invent a perfect ontology. You are turning topical research into a usable entity model that can become JSON-LD, stable @id references, and validation rules that match how your domain actually works.
A useful model usually covers these building blocks:
- Primary brand entity: the main subject every major page should reinforce
- Supporting entities: the related people, products, services, or ideas that add depth
- Relationship paths: the links that show how one concept depends on or connects to another
- Identity rules: the naming, @id, and sameAs conventions that keep references stable across pages
Your page architecture should follow the structured implementation guide for topical authority so hubs, spokes, and supporting pages reinforce the same semantic map. That connection is what makes structured data useful instead of decorative.
At larger scale, schema alone is not the full system. The strongest programs connect structured data, internal links, external mentions, and continuous auditing so the graph stays trustworthy as the site grows. Structured data can help make a page easier for search and AI systems to interpret, but it should be treated as one signal rather than a guarantee of AI citations (source). The real goal is a machine-readable model that reflects how your domain actually works, then keeps that model consistent as new pages ship.
How Do You Map Your Core Entities?
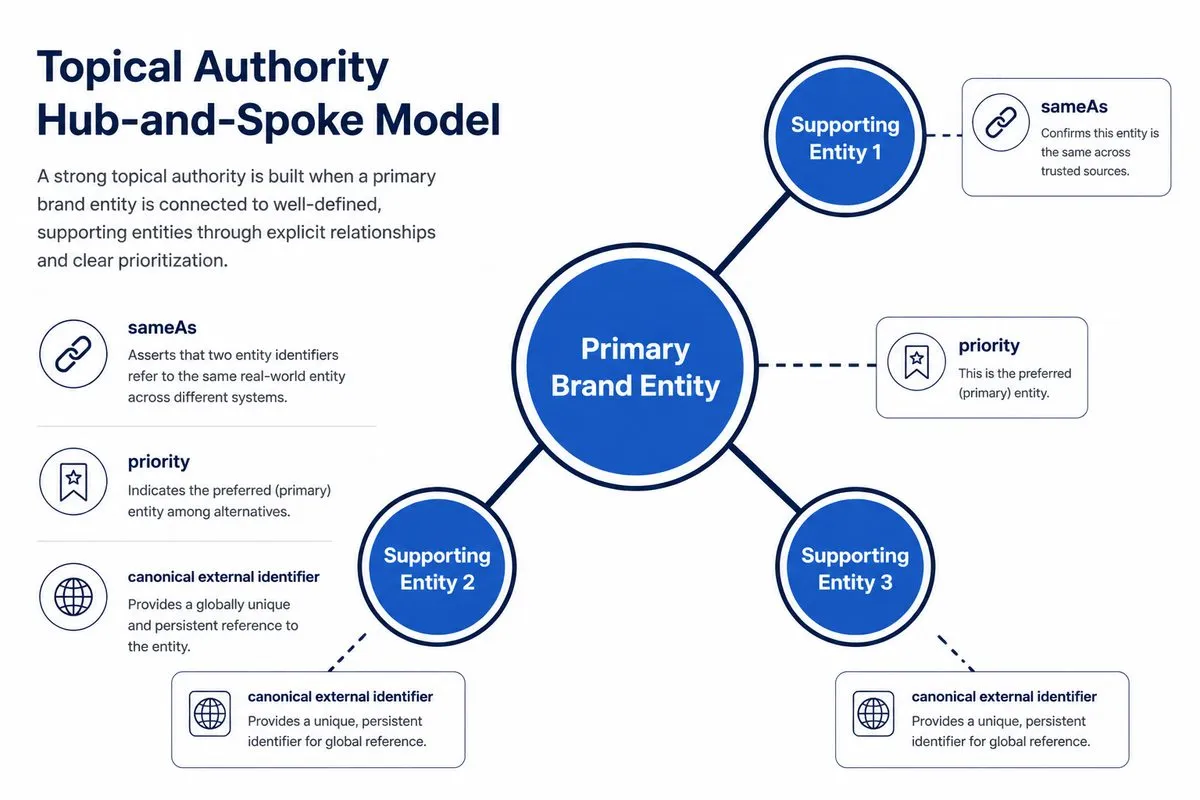
A usable topical authority map starts narrow. You define the pillar topic first, then map the core entities the page needs to feel complete. Supporting concepts belong in the cluster, but they should not crowd the pillar page.
Evidence should drive the inventory. Pull signals from top-ranking competitors, Search Engine Results Page (SERP) patterns, AI answers, and your own drafts. The recurring terms that survive that review usually reflect real intent, not topical bloat. That is where semantic clustering and entity recognition become practical filters instead of buzzwords.
Well-structured internal linking keeps the hierarchy steady across the site, so the entity layer does not drift from page to page.
A simple row structure keeps the work usable for SEO, content, and engineering teams:
| Core topic entity | Supporting concept | Canonical external identifier | Priority sameAs target |
|---|---|---|---|
| Main pillar subject | Related subtopic or modifier | Wikidata Q-ID or Wikipedia schema reference | Strongest public profile first |
| Brand, person, product, or organization | Adjacent concept that supports the page | Official database or knowledge graph identifier | Most trusted identity source available |
The about property should stay limited to the one to three primary subjects the page truly owns. Secondary concepts work better as plain mentions because they preserve semantic focus and keep the pillar entity distinct from supporting cluster entities. That restraint also helps search systems read the page with less signal dilution.
sameAs URLs should follow trust and relevance, not sheer volume. Use the most authoritative and consistent identity source available for the entity, such as an official site or a verified public profile, and avoid adding weak or inconsistent profiles that do not match the entity record (source). For people, the best targets are the sources that show a real, verifiable footprint.
Before you finalize the map, check three things:
- Digital footprint strength: The author and brand entities have enough public evidence to support the schema you publish.
- Identity source quality: The sameAs URLs point to trusted references that search systems and your audience already recognize.
- Content support: Internal linking, external mentions, and query satisfaction all reinforce the entity story instead of leaving it isolated.
Schema is only one signal in the broader authority system. It makes relationships machine-readable for GEO and LLM citation behaviors, but it still depends on content depth, entity coverage, internal linking, external mentions, user engagement, and query satisfaction. Build the entity layer with that full system in mind, and your topical authority map becomes far easier to trust.
How Do You Build A Production JSON-LD Graph?
A production JSON-LD graph works best as one connected unit, not a stack of disconnected schema blocks. Use one primary Article-type node for the page when appropriate, then connect the author and publisher with stable entity IDs so the markup stays readable and consistent for search systems (source). This is structured data with a job to do.
{ "@context": "https://schema.org", "@graph": [ { "@type": ["Article", "TechArticle", "BlogPosting"], "@id": "https://example.com/article-slug/#article", "url": "https://example.com/article-slug/", "headline": "Production JSON-LD Graph Example", "datePublished": "2026-05-01", "dateModified": "2026-05-20", "mainEntityOfPage": { "@id": "https://example.com/article-slug/" }, "author": { "@id": "https://example.com/article-slug/#author" }, "publisher": { "@id": "https://example.com/article-slug/#organization" }, "mainEntity": { "@id": "https://example.com/article-slug/#topic" }, "about": [ { "@id": "https://example.com/article-slug/#topic" } ], "mentions": [ { "@id": "https://example.com/article-slug/#related-entity" } ] }, { "@type": "Person", "@id": "https://example.com/article-slug/#author", "name": "Author Name", "jobTitle": "SEO Strategist", "sameAs": [ "https://www.linkedin.com/in/example", "https://x.com/example" ] }, { "@type": "Organization", "@id": "https://example.com/article-slug/#organization", "name": "Brand Name", "url": "https://example.com/", "logo": { "@type": "ImageObject", "url": "https://example.com/logo.png" }, "sameAs": [ "https://www.linkedin.com/company/example", "https://www.wikidata.org/wiki/Q123456" ] } ]}Stable fragment URIs matter more than teams often expect. Permanent IDs like #article, #author, and #organization should stay fixed across deploys, CMS slug changes, and content updates. That keeps entity resolution intact even when the visible URL shifts.
The production fields that strengthen entity understanding are straightforward:
- sameAs: verified profiles for the author and the organization
- logo: a real brand logo inside the Organization schema
- jobTitle: a role that matches the public byline
- about property: the core topic entity
- mentions property: supporting entities that appear in the article but are not the main focus
The site architecture patterns for entity-backed clusters fit this order because your schema should mirror the same entities your internal links already reinforce.
A repeatable production workflow keeps the graph honest:
- Define the content layer and the page’s angle.
- Extract entities from the page copy and supporting assets.
- Map each entity to a stable Knowledge Graph
@id. - Inject the JSON-LD in the template or CMS layer.
- Reinforce the same entities through internal links.
- Audit entity coverage after launch and after major updates.
A quick validation pass should happen before release. Nested relationships should resolve cleanly. Every sameAs target should be real and relevant. Each referenced entity should exist on-page or in a trusted profile. The @graph should also match visible author and publisher evidence, because mismatches weaken trust for SEO and GEO.
| Check | What good looks like |
|---|---|
| Node resolution | Every @id points to a stable, reachable entity |
| Relationship integrity | author, publisher, mainEntity, about, and mentions connect cleanly |
| Identity proof | sameAs links point to verified public profiles |
| Content match | Schema details match the page copy and byline |
| Entity coverage | Core and supporting entities reflect the actual topic map |
When you build the graph this way, structured data stops acting like a checkbox and starts working as a proof layer. That is the production blueprint for SEO and GEO, because it connects topical coverage, provenance, and brand authority in a form AI systems can cite and reuse.
How Do You Create Stable @id URIs?
Stable @id URIs start with one canonical pattern and stay fixed after publish. In JSON-LD, that pattern should be human-readable, lowercased, hyphenated, and free of campaign dates or other volatile strings. When the title, slug, or content order changes, the identifier still needs to point to the same entity.
You should also reserve one unique @id for each distinct entity and reuse it across the full @graph. That is the core of entity resolution in schema.org. It keeps the same Person, Organization, WebPage, or Article from being split into multiple nodes.
Before publishing, normalize the identifier format across everything that touches structured data:
- Strip tracking parameters from any URI used in schema
- Normalize trailing slashes so one version always wins
- Standardize case so every identifier follows the same lowercase pattern
- Choose one namespace for anchors and page-level IDs
- Reuse the same exact naming in schema, visible bios, and brand copy
A simple naming convention keeps the structure predictable. For author and organization pages, #author-name and #organization-name work well when they match the public brand name on site and social profiles. That alignment reduces drift, supports clearer Person schema and Organization schema signals, and strengthens sameAs URLs across the rest of the web.
| Entity | Stable pattern | Why it stays durable |
|---|---|---|
| Article | #article-name or a fixed path | Survives title and slug edits |
| Person | #author-name | Ties the author profile to one node |
| Organization | #organization-name | Matches one exact brand identity |
| WebPage | #webpage-name | Separates page identity from article content |
Map the stable Article @id to mainEntity, then connect supporting nodes with about and mentions. That tells crawlers what the page is mainly about and which related entities are referenced. Use the same entity IDs on the author page and organization page so visible copy, internal links, and the markup all reinforce the same signals. Treat each @id as a permanent reference, not a page label, and you build a durable topical authority graph instead of a shallow schema cluster.
How Do You Validate And Troubleshoot Schema?
Schema validation works best as a layered check. Fix syntax first, then test entity links, then confirm the live page matches the graph you meant to publish.
A clean JSON-LD file can still fail in practice. The safest workflow is to validate structure, confirm connections, then compare what you marked up with what search engines can actually crawl.
- Run the structure pass first. Test your schema markup in the Google Rich Results Test and the Schema Markup Validator before publishing. Fix parse errors, missing commas, malformed braces, and unsupported nesting before anything else, because those problems block every later check.
- Confirm the graph is connected, not just valid. Link WebPage, Article, Person, and Organization nodes with stable
@idvalues such as#authorand#organization. That lets search engines trace the entity chain instead of treating each block as a disconnected snippet. It works like internal linking for entities, not just code. - Audit every
@idandsameAstarget. Click each referenced anchor and confirm it resolves on the live page. Keep IDs stable across deploys and CMS edits, since broken@idpaths often show up as orphaned nodes, missing authorship, or collapsed entity chains. ForsameAs, use authoritative identifiers from Wikidata, Wikipedia schema references, or other verified entity IDs only when they point to the exact real-world match. - Tighten entity resolution when names are ambiguous. A person, brand, or topic with a common name needs stronger context. Add occupation, brand affiliation, homepage, and corroborating
sameAstargets so the Knowledge Graph can resolve the entity without guesswork. Lookalike profiles create noisy signals and weaken the match. - Review nesting for semantic clarity. Keep nested nodes where the relationship is real. Avoid burying key signals so deeply that author and organization meaning gets lost. Many plugin-generated clusters are technically valid but semantically shallow, which makes them harder to interpret.
- Compare the live page after deployment. Check the rendered source, the JSON-LD output, and the indexed URL signals side by side. If the visible content and the graph diverge, correct the mismatch before requesting reindexing.
This order catches syntax errors, broken references, bad sameAs matches, disambiguation mistakes, and over-nesting in the right sequence. Use the same review pattern every time so your schema stays reliable as the site grows.
How Do You Measure Topical Authority Gains?
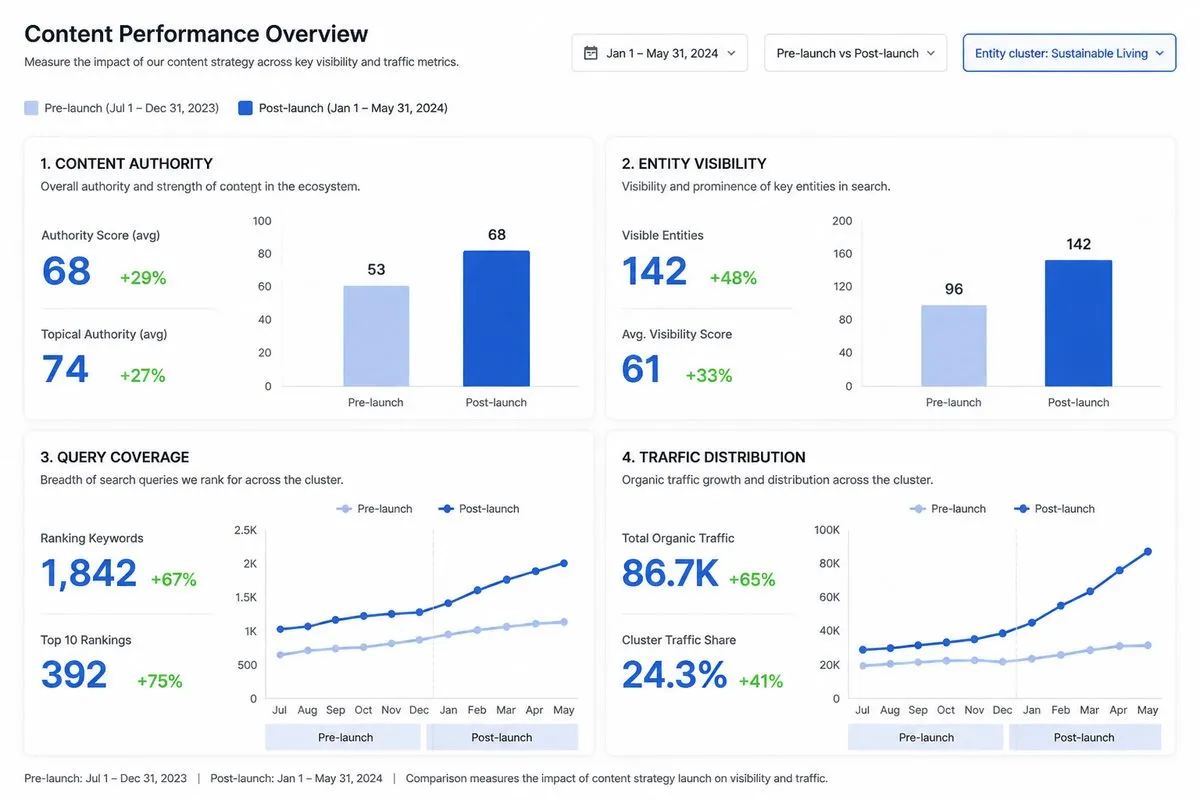
A solid measurement plan starts before the next JSON-LD update goes live. To prove topical authority gains, build a baseline scorecard first and compare it after implementation instead of reading meaning into impressions or gut feel.
Use four core scores to keep the picture balanced:
| Metric | What it measures | Why it matters |
|---|---|---|
| Content Authority | Depth, coverage, and usefulness across the topic | Shows whether the cluster answers the full intent set |
| Market Authority | Visibility versus competitors in the same topic space | Shows whether your brand owns more of the conversation |
| AI Authority | Presence and reuse in AI answers and summaries | Shows whether machines treat your brand as a usable source |
| Topical Authority Score (TAS) | A combined view of the three signals above | Gives you a clean before-and-after comparison |
That scorecard works best when you pair it with entity-level tracking. In entity-based SEO, a practical goal is to track whether core entities become more visible in branded queries, knowledge features, and AI answers after schema changes, while treating the schema graph as one input among several (source). Schema is machine-readable confirmation, but you still need to validate the lift with content depth, internal linking, external mentions, and query satisfaction.
A topical authority map gives the analysis its structure. Once semantic clustering groups related queries and pages, you can see whether the topic is gaining breadth or just piling visits onto one head term. Healthy movement usually shows wider traffic across the hub, stronger support-page visits, and less dependence on a single URL carrying the load.
Track these signals together:
- Knowledge visibility: Watch whether your brand, product, or expert entity appears in knowledge panels, related entity cards, and similar Google knowledge features.
- Query coverage: Compare branded entity searches with the queries attached to each cluster.
- Semantic rankings: Follow the pages tied to each entity cluster and check whether mid-funnel and long-tail queries spread across the hub.
- Traffic distribution: Compare pre-launch and post-launch visits by page type, query intent, and entity cluster.
Measurement also needs a cadence that matches how authority compounds. A monthly entity and schema review, a biweekly check on indexation and rich result eligibility, and a quarterly authority review keep the data useful.
That cadence helps you separate real gains from noise. A ranking jump can land beside content edits, internal link changes, or crawl improvements. Treat a schema change as a valid driver only when those signals move together over time across SEO and GEO surfaces.
Tooling should match the same discipline. Google Search Console, GA4, rank tracking, schema validation, log files, and an AI visibility tracker give you the raw material. From there, compare pre-launch and post-launch performance by entity cluster, query intent, and page type so you can tell whether topical authority is expanding or simply shifting around.
The cleanest proof is simple. If traffic distribution gets healthier, schema reinforces entity visibility, and semantic rankings spread across the cluster, your topical authority is moving in the right direction. This is measurement guidance, not financial advice.
Entity Schema For Topical Authority FAQs
These FAQs cover the practical questions SEO teams ask as entity schema shapes topical authority. You’ll get a clearer view of structure, entity mapping, and the checks that matter before you trust the markup.
How Many Entities Should A Hub Include?
A good rule is to keep the hub’s about property tight. That keeps the semantic signal tight and makes the page read as one clear topical center. Put secondary concepts in body copy as mentions. If a topic starts to need more than three to five meaningful entities, split it into a separate hub or supporting page so your structured data stays focused.
Should Every Entity Get Its Own Schema?
You do not need a separate schema node for every entity. Use a standalone node when the entity is central and has enough content depth for page-level detail. It should also support a stable canonical name, a clear @id, and strong external IDs or sameAs targets. If the name shifts or the entity is only one part of a broader topic, keep it nested as a supporting Thing inside about or mentions so the main entity stays explicit and the page stays focused.
When Should You Use SameAs Links?
sameAs works best when the entity already has a clear, authoritative identity and you want to reduce confusion around organizations, authors, products, local businesses, or known brands. Point it to a canonical profile such as Wikidata, Wikipedia, LinkedIn, an official social account, or an industry association only when that source describes the exact same entity. Check that the name, description, URL, context, and NAP details all line up, because the link should strengthen knowledge graph alignment, not create ambiguity. If the entity is still unclear, use the most specific source and wait until the external profile maps cleanly to your target.
How Often Should You Update Entity Schema?
Update entity schema on a rolling cadence, but don’t wait for the next review cycle when the content layer changes. Fresh research, updated stats, new pages, and a shift in topical focus should move through entity extraction, Knowledge Graph mapping, schema injection, and internal link reinforcement right away. Recheck author and organization entities when bylines, credentials, brand ownership, or contributor relationships change, and treat mergers, rebrands, URL changes, and canonical errors as triggers for JSON-LD validity checks, stable IDs, anchor consistency, missing required properties, and continuous entity coverage auditing when AI Search or crawl data shows drift.
Do Internal Links Strengthen Entity Schema?
Yes, internal links strengthen entity schema when your anchor text, URL structure, and breadcrumbs all reinforce the same topical hierarchy. Internal linking gives you the page-level relationship map, while schema confirms those parent, child, and sibling connections in machine-readable form. To check the fit, compare anchor text with schema labels, make sure linked pages sit in the same entity node or a close variant, and verify that navigation, URLs, and JSON-LD all point to the same topical hierarchy.
About the author

Yoyao Hsueh
Yoyao Hsueh is the founder of Floyi and TopicalMap.com with over seven years of hands-on SEO experience. He has built topical maps and consulted on content strategies and SEO plans for more than 300 clients. He created Topical Maps Unlocked, a program thousands of SEOs and digital marketers have studied to build topical authority. He works with SEO teams and content leaders who want their sites to become the source traditional and AI search engines trust.
About Floyi
Floyi is a closed loop system for strategic content. It connects brand foundations, audience insights, topical research, maps, briefs, and publishing so every new article builds real topical authority.
See the Floyi workflow